package|Pandas
Pandas官网
Series
由一组数据以及与之相关的数据标签 (索引) 构成
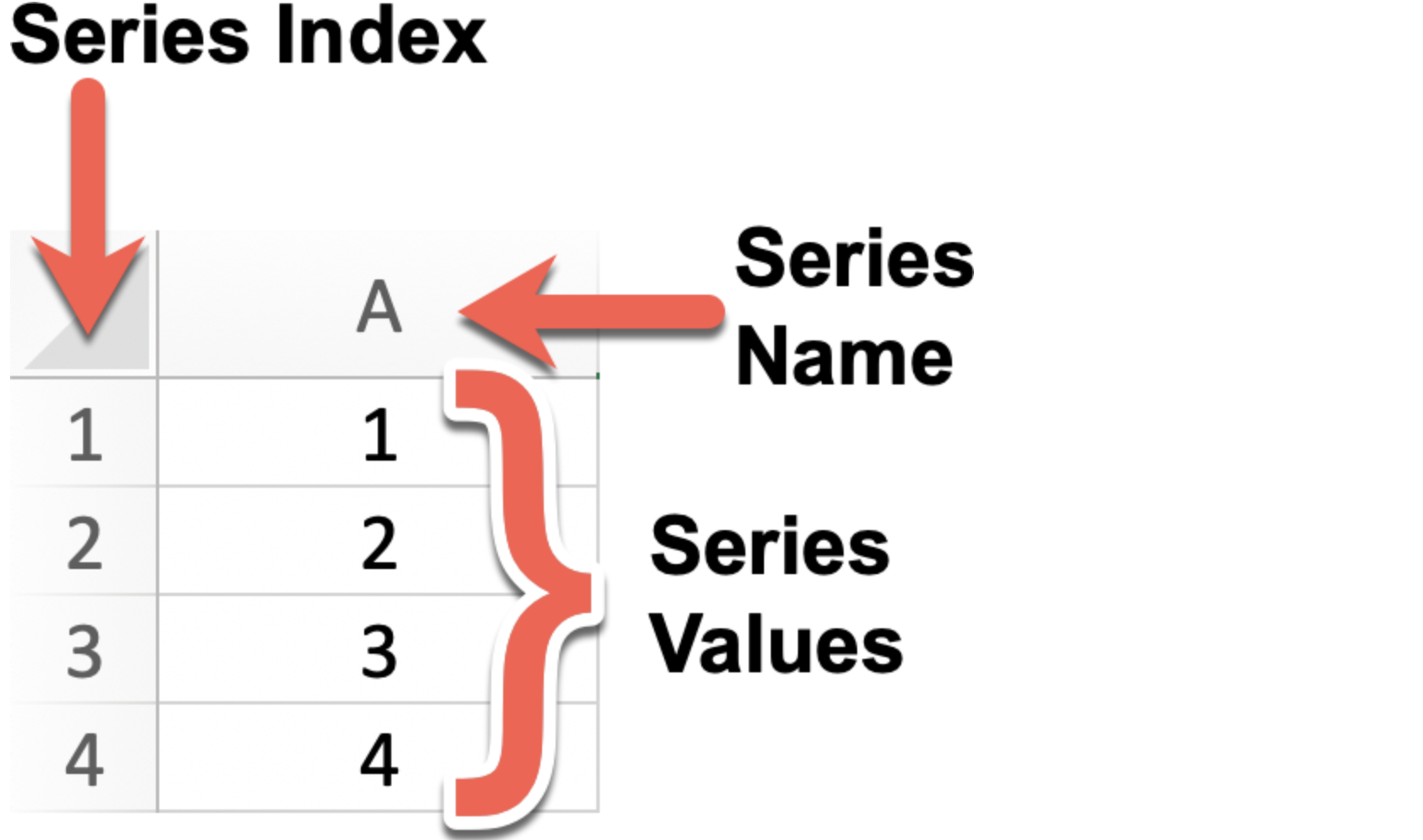
创建Series
| pandas.Series(data=None, index=None, dtype=None, name=None, copy=False, fastpath=False)
|
| custom_index = [1, 2, 3, 4] # 自定义索引
series = pd.Series([1, 2, 3, 4], index=custom_index, name = 'A')
|
dtype 指定 Series 的数据类型。可以是 NumPy 的数据类型,例如 np.int64、np.float64 等。如果不提供此参数,则自动推断
我们也可以用字典来创建Series
| sites = {1: "Google", 2: "Runoob", 3: "Wiki"}
myvar = pd.Series(sites)
|
DataFrame
tbc
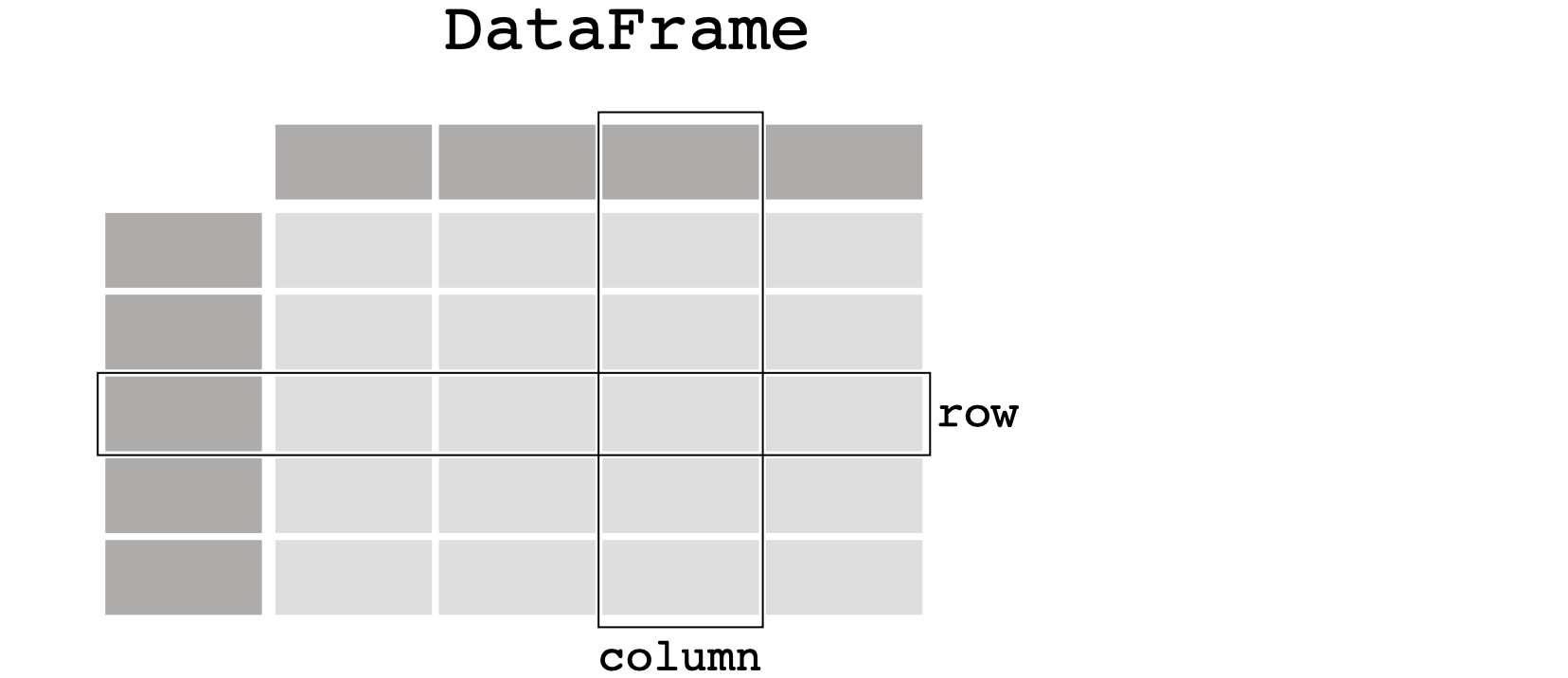
index-key-value
创建DataFrame
| pandas.DataFrame(data=None, index=None, columns=None, dtype=None, copy=False)
|
使用列表创建
| data = [['Google', 10], ['Runoob', 12], ['Wiki', 13]]
df = pd.DataFrame(data, columns=['Site', 'Age'])
# 设置每列的数据类型
df['Site'] = df['Site'].astype(str)
df['Age'] = df['Age'].astype(float)
print(df)
|
输出
| Site Age
0 Google 10.0
1 Runoob 12.0
2 Wiki 13.0
|
使用字典创建
| data = {'Site': ['Google', 'Runoob', 'Wiki'], 'Age':[10, 12, 13]}
df = pd.DataFrame(data)
|
Series合并为DataFrame
| apples = pd.Series([1, 2, 3, 4])
bananas = pd.Series([2, 6, 3, 5])
df = pd.DataFrame({'Apples': apples, 'Bananas': bananas})
|
提取行
loc[n] 返回指定行
| data = {
"calories": [420, 380, 390],
"duration": [50, 40, 45]
}
df = pd.DataFrame(data)
print(df.loc[0])
|
loc[[0, 2, ...]] 返回多行
CSV文件
读取CSV文件
| df = pd.read_csv('nba.csv', sep=',', header=0, names=['Name', 'Team', 'Number'], dtype={'Name': str, 'Team': str, 'Number': float})
|
会输出完整的DataFrame,而 print(df) 输出前后5行
数据处理
head(n) 读取前n行,tail(n) 读取后n行